DATA GOVERNANCE
Gouvernance des données : à quoi sert-elle vraiment (et à quoi ne sert-elle pas) ?
.png)
12/2/2026
La gouvernance des données est un de ces sujets qui reviennent systématiquement dès qu’une organisation commence à parler sérieusement de transformation data. Elle apparaît dans les stratégies, dans les appels d’offres, dans les roadmaps des directions SI, et dans les discussions de couloir dès qu’un KPI “ne sort pas comme avant”. Le problème, c’est qu’on la cite souvent comme une évidence, sans vraiment s’arrêter sur ce qu’elle recouvre. Et comme beaucoup de concepts devenus incontournables, elle a fini par se charger de toutes sortes de promesses, parfois réalistes, parfois beaucoup moins.
Dans l’imaginaire collectif des entreprises, la gouvernance des données est parfois perçue comme une sorte de grand plan de mise en ordre. Une démarche qui va enfin mettre tout le monde d’accord, corriger les incohérences, rendre les données fiables, fluidifier les projets et sécuriser les usages. Autrement dit : un cadre structurant, mais aussi, soyons honnêtes, un espoir un peu magique. Car si l’on pouvait résoudre les conflits de définition, les problèmes de qualité, les incohérences entre outils et les zones grises de responsabilité en lançant simplement “un programme de gouvernance”, cela se saurait depuis longtemps.
La réalité est plus nuancée. La gouvernance des données n’est ni une solution technique, ni un simple dispositif de conformité, ni une série de comités qui se réunissent pour valider des documents. C’est avant tout un mécanisme organisationnel. Un cadre qui vise à structurer la manière dont l’entreprise définit, pilote et arbitre ses règles liées à la donnée. Dit autrement : la gouvernance sert à éviter que les données soient utilisées, modifiées, interprétées ou partagées sans que personne ne sache clairement qui en est responsable, qui décide des règles, et comment ces règles évoluent dans le temps.
C’est précisément pour cela que la question “à quoi sert-elle vraiment ?” mérite d’être posée. Car tant que cette question n’est pas clarifiée, la gouvernance risque d’être mal positionnée. Et une gouvernance mal positionnée est souvent une gouvernance qui échoue : soit parce qu’on en attend trop et qu’elle déçoit, soit parce qu’on la réduit à un exercice bureaucratique, et qu’elle devient un frein plutôt qu’un levier.
La question mérite d’être posée parce que la gouvernance des données est devenue un réflexe quasi automatique dès qu’une organisation parle de transformation data. On la cite comme une évidence, un passage obligé, un signe de maturité. Mais dans les faits, beaucoup de programmes de gouvernance démarrent sans que l’on prenne réellement le temps de clarifier ce qu’on en attend. On sait qu’il “faut” de la gouvernance, mais on ne sait pas toujours quel problème précis elle est censée résoudre : harmoniser des définitions ? sécuriser les accès ? éviter les conflits entre métiers ? cadrer la conformité ? Souvent, la réponse est “un peu tout ça”, ce qui est exactement le meilleur moyen de lancer un dispositif ambitieux sans jamais pouvoir mesurer s’il fonctionne.
La deuxième raison, c’est que la gouvernance est l’un des sujets les plus souvent mal interprétés, y compris par des personnes très compétentes. Elle est régulièrement confondue avec la qualité des données, avec le data management, avec l’architecture, ou même avec un outil (catalogue, MDM, plateforme de data quality). Or, la gouvernance n’est pas là pour transformer les données à la place des équipes, ni pour corriger un modèle mal conçu, ni pour stabiliser un pipeline capricieux. Elle sert d’abord à organiser la prise de décision autour de la donnée : qui définit quoi, qui arbitre, qui est responsable, et comment les règles évoluent. Dit autrement, elle ne fait pas le travail à la place des gens, elle évite surtout que personne ne sache qui est censé le faire.
Enfin, la question mérite d’être posée parce que la gouvernance est un cadre qui peut autant aider qu’handicaper. Bien conçue, elle sécurise les usages, aligne les métiers et rend les projets plus durables. Mal conçue, elle se transforme en mille validations, en comités qui s’empilent, en règles floues, et en documents que personne ne lit — sauf peut-être une fois par an, juste avant un audit. Clarifier à quoi elle sert réellement, c’est donc éviter deux erreurs classiques : en attendre des miracles, ou la rejeter comme une bureaucratie inutile. Et dans les deux cas, l’entreprise y perd : soit en déception, soit en désorganisation.
La gouvernance des données n’est pas un concept théorique réservé aux grandes entreprises ou aux environnements ultra-réglementés. Dans la pratique, elle répond à un besoin très concret : éviter que la donnée soit un actif critique géré de manière implicite, avec des règles non dites, des définitions qui varient selon les équipes, et des décisions prises au cas par cas. Une gouvernance bien conçue ne cherche pas à tout contrôler, mais à donner un cadre clair pour que les données puissent être utilisées de manière fiable, cohérente et durable. Et surtout : sans dépendre d’une poignée de personnes ou d’une “connaissance historique” difficile à transmettre.
La gouvernance des données correspond au cadre qui permet à une organisation de définir des règles communes sur ses données, de clarifier les responsabilités, et d’arbitrer les décisions importantes (définitions, accès, usages, référentiels). Elle ne remplace pas les projets data, mais elle évite qu’ils reposent uniquement sur des habitudes, des interprétations locales ou sur la personne qui “sait comment ça marche”.
La gouvernance des données sert avant tout à clarifier qui est responsable de quoi. Sans ce cadre, les règles restent implicites, les décisions sont prises au cas par cas, et dès qu’un désaccord apparaît, plus personne ne sait vraiment qui doit trancher. En structurant les rôles et les responsabilités, la gouvernance évite que la donnée soit “à tout le monde” donc à personne, et elle rend enfin possible des arbitrages cohérents dans la durée.
👉À lire aussi : Définir les rôles et responsabilités en matière de gouvernance des données
La première utilité concrète de la gouvernance, c’est de rendre explicite la responsabilité. Pas dans un sens théorique (“tout le monde est concerné”), mais dans un sens opérationnel : qui répond quand ça ne va pas, et qui a le mandat pour faire évoluer les règles.
Quand ces responsabilités sont claires, les sujets data deviennent plus simples à traiter : on sait qui solliciter, qui arbitrer, et surtout, qui ne pas solliciter inutilement.
Sans gouvernance, les définitions et règles de gestion se construisent souvent de manière implicite, au fil des projets, et parfois même au fil des dashboards. La gouvernance permet d’installer un principe simple : les règles doivent être décidées par des acteurs légitimes, pas par la personne qui a construit le dernier rapport.
Ce point est souvent sous-estimé, alors qu’il est central : la gouvernance évite que les règles métier soient produites par accident.
C’est l’un des problèmes les plus fréquents dans les organisations : la donnée est considérée comme un sujet collectif, donc personne ne s’en empare réellement. Et quand tout le monde est responsable, la réalité est simple : personne ne l’est.
👉À lire aussi : Data Owner, Data Steward, Data Custodian : le triptyque pour réussir sa gouvernance des données
Ce mécanisme évite un phénomène très classique : une organisation où la data est partout dans les discours mais nulle part dans la responsabilité.
La gouvernance des données sert aussi à éviter un grand classique : des équipes qui utilisent les mêmes mots, mais pas les mêmes définitions. En posant des KPI communs, des référentiels partagés et des règles d’arbitrage, elle réduit les incompréhensions, les dashboards contradictoires et les débats sans fin sur “le bon chiffre”. Et, au passage, elle permet enfin de passer de la discussion sur les définitions à la discussion sur les décisions.
Les KPI sont au cœur du pilotage de la performance. Pourtant, dans de nombreuses organisations, ils reposent sur des interprétations différentes selon les équipes, les outils ou les contextes d’usage. La gouvernance des données intervient précisément pour éviter cette fragmentation et garantir que lorsqu’un indicateur est présenté en comité de direction, tout le monde parle bien du même calcul.
Une définition unique ne garantit pas que tout le monde sera toujours d’accord, mais elle garantit au moins que les désaccords portent sur la stratégie et non sur le calcul.
Les référentiels structurent la donnée : clients, produits, fournisseurs, entités organisationnelles. Lorsqu’ils ne sont pas stabilisés, les incohérences se propagent dans l’ensemble des analyses et des projets. La gouvernance permet de traiter ces référentiels comme des actifs structurants, et non comme de simples tables techniques.
Un référentiel partagé n’est pas un luxe organisationnel ; c’est souvent la condition minimale pour produire des analyses comparables et fiables.
Dans toute organisation, les métiers n’ont pas toujours la même lecture d’un indicateur ou d’un périmètre. Ces divergences sont normales, mais sans cadre, elles deviennent chroniques. La gouvernance offre un mécanisme structuré pour transformer ces désaccords en décisions assumées.
Ce cadre ne supprime pas les débats — et c’est heureux — mais il évite qu’ils deviennent permanents et improductifs.
Lorsqu’une organisation souhaite aligner ses définitions ou stabiliser ses référentiels, la tentation est forte de démarrer par un outil : catalogue, MDM, glossaire, workflow de validation. Or, sans accord préalable sur les rôles, les responsabilités et le processus d’arbitrage, l’outil ne fera que formaliser le désordre existant. Une bonne pratique consiste à commencer par identifier les domaines critiques (KPI stratégiques, référentiels structurants), à nommer les responsables légitimes, et à définir un mécanisme simple d’arbitrage. L’outillage vient ensuite soutenir ce cadre, pas le remplacer. En matière de gouvernance, la technologie accélère mais elle ne décide pas à votre place.
La gouvernance des données n’est pas seulement un sujet de performance ou de cohérence métier : c’est aussi un sujet de maîtrise des risques. Dès lors que la donnée est utilisée pour prendre des décisions, produire des reportings sensibles, automatiser des actions ou traiter des informations personnelles, elle devient un actif qui doit être encadré. Et dans ce contexte, l’absence de gouvernance ne crée pas uniquement des incohérences, elle crée des vulnérabilités.
La conformité est souvent l’un des déclencheurs historiques des démarches de gouvernance, et pour une bonne raison : les obligations légales exigent de pouvoir démontrer qui fait quoi, avec quelles données, et selon quelles règles.
La gouvernance ne remplace pas les équipes juridiques, mais elle permet de rendre leurs exigences applicables et suivables dans la durée.
Les problèmes d’accès aux données sont rarement théoriques. Ils se traduisent soit par des accès trop larges (et donc risqués), soit par des accès trop restreints (et donc bloquants). La gouvernance sert à structurer une approche cohérente.
L’objectif n’est pas de bloquer les usages, mais de rendre l’accès à la donnée explicite, contrôlé et réversible.
Dans un environnement data moderne, la donnée circule : elle est transformée, agrégée, exportée, utilisée dans des dashboards, parfois intégrée à des modèles ou à des automatisations. Sans traçabilité, il devient très difficile de comprendre ce qui a été utilisé, comment, et avec quel impact.
La traçabilité ne sert pas à “surveiller” les équipes : elle sert surtout à éviter que la donnée devienne une boîte noire.
Un projet data peut fonctionner sans gouvernance mais souvent seulement pendant un certain temps. Au démarrage, tout va vite : les équipes sont proches, les décisions sont prises à l’oral, les règles sont implicites, et les connaissances sont concentrées chez quelques personnes clés. Mais dès que l’organisation grandit, que les projets se multiplient, ou que les équipes changent, la fragilité apparaît : définitions qui divergent, référentiels qui se dédoublent, règles qui ne sont plus comprises, et dépendance excessive à certains profils. La gouvernance sert précisément à éviter que la valeur produite par les projets data soit temporaire. Elle transforme des décisions ponctuelles en cadre durable, et permet aux projets de survivre au temps, aux évolutions d’outils, et aux départs.
Dans beaucoup d’organisations, la plateforme data repose sur des personnes “clés”, qui connaissent les règles, les exceptions, les historiques, et parfois même les incohérences. Tant qu’elles sont là, tout semble fonctionner. Mais dès qu’elles changent de poste, quittent l’entreprise ou deviennent indisponibles, les projets ralentissent brutalement, ou deviennent impossibles à maintenir.
En clair, la gouvernance permet d’éviter qu’un projet data soit “robuste” uniquement tant que la bonne personne est dans l’équipe.
Sans gouvernance, les règles de gestion se construisent au fil des projets : un KPI est défini dans un dashboard, une exception est ajoutée dans un modèle, une convention est adoptée dans un fichier local. Avec le temps, ces règles deviennent difficiles à retracer, et encore plus difficiles à faire évoluer.
La formalisation n’a pas pour but de produire des documents pour le plaisir : elle sert à rendre les projets maintenables et compréhensibles.
👉À lire aussi : Quelles règles de gouvernance des données sont réellement utiles ?
Les référentiels sont le socle de la cohérence analytique. Mais dans la durée, ils ont tendance à se fragmenter : différentes versions d’un client, plusieurs nomenclatures produits, des structures organisationnelles non alignées, des canaux de vente interprétés différemment. Et chaque divergence finit par créer des écarts dans les analyses.
Stabiliser les référentiels, ce n’est pas chercher la perfection : c’est éviter que l’organisation produise, année après année, plusieurs vérités concurrentes.
Un projet data peut fonctionner un temps sans règles formalisées, sans responsabilités claires et sans documentation structurée. Mais ce qui tient grâce à l’énergie des équipes ou à la mémoire d’un expert finit toujours par se fragiliser. Évitez de laisser les règles critiques uniquement dans le code ou dans la tête de quelques personnes. La gouvernance n’est pas là pour ralentir, mais pour éviter que le projet ne repose sur des fondations invisibles et donc instables.
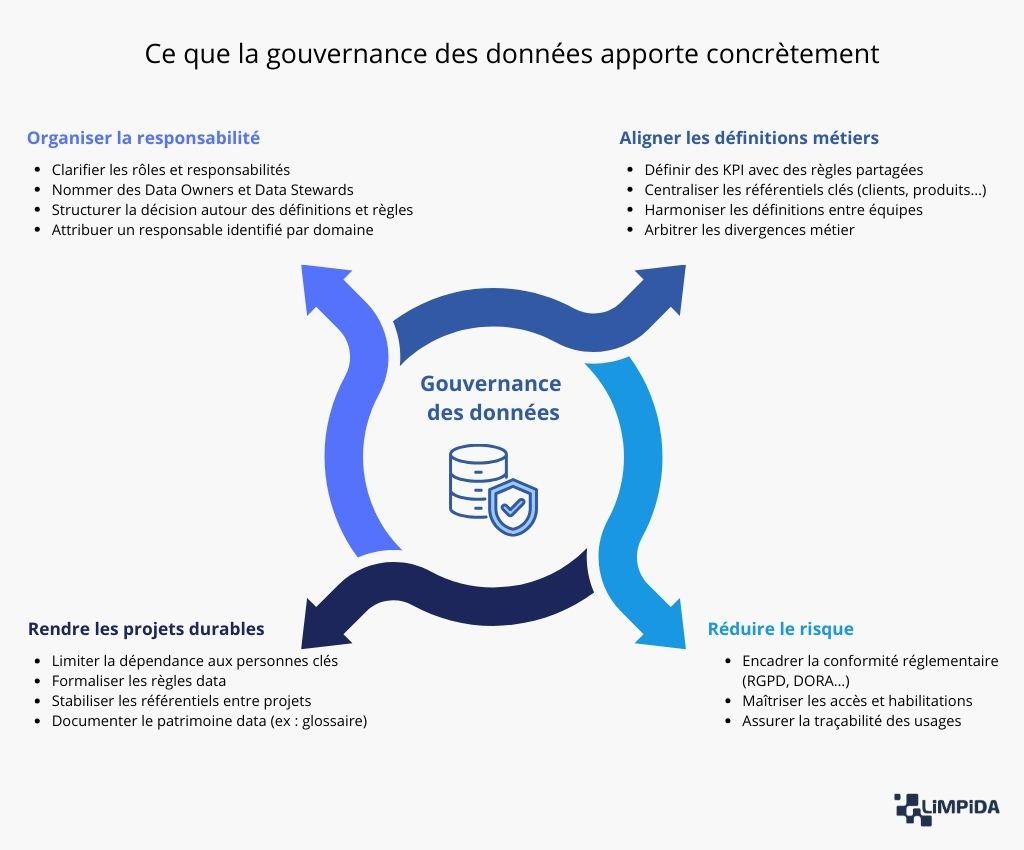
La gouvernance des données est souvent perçue comme une solution globale à tous les problèmes liés à la donnée. Et c’est compréhensible : quand les chiffres divergent, que les projets prennent du retard, que la qualité n’est pas au rendez-vous ou que les outils se multiplient, la gouvernance ressemble à une promesse d’ordre et de cohérence. Mais c’est précisément là que naît une grande partie des déceptions : la gouvernance est un cadre organisationnel, pas une baguette magique. Elle peut structurer les responsabilités, stabiliser les définitions et sécuriser les usages, mais elle ne remplace ni une architecture technique saine, ni des pipelines robustes, ni des choix de modélisation solides. Autrement dit : elle aide à mieux piloter la donnée, mais elle ne répare pas automatiquement ce qui est cassé.
La gouvernance des données ne corrigera jamais une modélisation mal conçue. Si les tables sont incohérentes, si les jointures sont fragiles, si les clés ne sont pas stables, ou si les notions métier ont été mal traduites dans le modèle, la gouvernance ne fera qu’ajouter un cadre autour d’un problème structurel. Elle peut aider à clarifier ce que le modèle devrait représenter, mais elle ne remplacera pas le travail d’architecture, de modélisation et de conception.
Dans la pratique, c’est un malentendu fréquent : on met en place des définitions, des rôles, des règles mais on continue à produire des analyses sur un socle qui ne tient pas. Résultat : la gouvernance est accusée de ne pas fonctionner, alors que le vrai problème est ailleurs. C’est un peu comme organiser un comité pour décider de la meilleure manière de circuler sur une route qui n’a jamais été asphaltée.
La gouvernance peut jouer un rôle utile, mais indirect : elle peut éviter que de nouvelles incohérences soient ajoutées, elle peut cadrer les conventions, elle peut imposer des standards de modélisation. Mais elle ne remplace pas la compétence technique. Une architecture fragile reste fragile, même si elle est très bien documentée.
La gouvernance des données n’a pas pour vocation de stabiliser des pipelines instables. Si les flux de données tombent régulièrement, si les transformations échouent sans alerte, si les temps de traitement explosent, ou si les dépendances entre outils sont mal maîtrisées, le problème est technique et opérationnel. La gouvernance peut définir des règles, mais elle ne va pas empêcher un job de planter à 2h du matin parce qu’une API a changé ou qu’un schéma a été modifié sans prévenir.
Ce point est important, car certaines organisations tentent de compenser une faiblesse technique par plus de validation et plus de processus. On multiplie les comités, on impose des étapes de validation supplémentaires, on crée des documents à remplir avant chaque changement. Cela peut donner l’impression de “mieux contrôler”, mais cela ne rend pas le pipeline plus robuste. Pire : cela ralentit les équipes sans traiter la cause racine, ce qui finit par créer une gouvernance perçue comme punitive.
La gouvernance peut néanmoins contribuer à éviter certains incidents, en structurant les responsabilités, en imposant des règles de changement, en clarifiant les standards de monitoring ou de documentation. Mais elle ne remplacera jamais les pratiques d’ingénierie : tests, observabilité, alerting, industrialisation. En résumé, un pipeline instable a besoin d’ingénierie pas d’un comité supplémentaire, même si celui-ci est très bien animé.
La qualité des données est souvent le premier problème visible dans une organisation : doublons, valeurs manquantes, incohérences, retards de mise à jour. Face à ces difficultés, la gouvernance est parfois présentée comme la solution naturelle. Pourtant, si elle peut structurer les responsabilités et poser des règles, elle ne nettoie pas les bases, ne corrige pas les anomalies et ne met pas en place les contrôles techniques. La qualité est un sujet opérationnel qui nécessite des actions concrètes. La gouvernance crée le cadre ; elle ne fait pas le travail à la place des équipes.
La gouvernance peut définir qu’un champ “date de naissance” est obligatoire, qu’un client doit avoir un identifiant unique, ou qu’un produit doit respecter une nomenclature précise. Mais écrire une règle dans un document, même validé en comité, ne garantit en rien qu’elle sera respectée dans les systèmes.
Dans la réalité, l’application d’une règle dépend des processus métiers, des interfaces utilisateurs, des contrôles dans les outils et des contraintes opérationnelles. Si un système autorise l’enregistrement d’un client sans email, ou si un import massif contourne les validations, la règle formalisée restera théorique. La gouvernance peut signaler l’écart, mais elle ne bloque pas techniquement l’erreur.
C’est un point clé : la gouvernance pose les exigences, mais leur application repose sur des mécanismes opérationnels. Sans intégration concrète dans les outils et les processus, les règles deviennent des intentions. Et en matière de qualité, les intentions ne suffisent pas.
Améliorer la qualité des données suppose des dispositifs techniques et organisationnels : contrôles automatiques, alertes, workflows de correction, indicateurs de suivi, routines de nettoyage. Ce sont des actions concrètes qui demandent du temps, des compétences et parfois des outils spécialisés.
La gouvernance peut prioriser les domaines critiques, désigner un responsable qualité, définir des seuils d’acceptabilité. Mais elle ne remplace pas les tests de cohérence, les règles de validation intégrées dans les systèmes, ni les processus de correction des anomalies. Sans ces mécanismes, la qualité reste dépendante de la vigilance humaine — ce qui est rarement une stratégie fiable à grande échelle.
Autrement dit, la gouvernance peut structurer la démarche qualité, mais elle ne l’automatise pas. Croire qu’un programme de gouvernance suffira à “améliorer la qualité” sans action technique et opérationnelle, c’est confondre cadre et exécution. Et la donnée, elle, ne fait pas cette confusion.
👉À lire aussi : Zoom sur les outils de gouvernance de données
La gouvernance des données est parfois présentée comme un levier de transformation culturelle. Et il est vrai qu’en structurant les rôles, les règles et les responsabilités, elle envoie un signal fort : la donnée compte, et elle mérite un cadre clair. Mais il faut être lucide : la gouvernance, à elle seule, ne crée pas une culture data. Elle peut poser des fondations, mais elle ne transforme pas automatiquement les comportements, ni les réflexes décisionnels des équipes.
Une culture data ne naît pas parce qu’un comité a été créé ou qu’un glossaire a été publié. Elle se construit lorsque les collaborateurs comprennent les indicateurs qu’ils utilisent, savent interpréter les analyses, et voient leurs managers prendre des décisions réellement fondées sur les données.
Cela suppose de la formation, de la pédagogie, de l’accompagnement, et surtout de l’exemplarité au niveau managérial. Si les décisions stratégiques continuent d’être prises “à l’intuition” sans référence aux analyses produites, la gouvernance, aussi structurée soit-elle, restera périphérique.
En d’autres termes, la culture data se développe par la pratique quotidienne. Les règles peuvent structurer le cadre, mais ce sont les usages réels qui transforment les mentalités.
La gouvernance peut définir des rôles, des processus et des responsabilités. Elle peut imposer des standards, clarifier les définitions et organiser les arbitrages. Mais elle ne peut pas forcer l’adhésion. L’engagement des équipes repose sur leur compréhension des enjeux et sur la valeur qu’elles perçoivent dans l’usage de la donnée.
Si la gouvernance est perçue comme une contrainte administrative supplémentaire, elle risque même de produire l’effet inverse : une mise à distance du sujet data. À l’inverse, lorsqu’elle est articulée avec des cas d’usage concrets et des bénéfices visibles, elle devient un cadre facilitateur.
La gouvernance est donc un support, pas un moteur culturel. Elle peut créer les conditions favorables, mais la dynamique culturelle dépend avant tout des pratiques, du leadership et de l’appropriation par les métiers.
La gouvernance des données est souvent mise en place pour sécuriser et structurer les projets. Mais mal conçue, elle peut produire l’effet inverse de celui recherché. Lorsqu’elle devient excessive, mal dimensionnée ou déconnectée des réalités opérationnelles, elle ralentit les initiatives au lieu de les soutenir. Et c’est généralement à ce moment-là qu’on commence à entendre que “la gouvernance bloque tout”. En réalité, ce n’est pas la gouvernance en soi qui pose problème, mais la manière dont elle est déployée.
👉À lire aussi : Comment éviter que la gouvernance des données devienne une usine à gaz ?
Dans une volonté de contrôle, certaines organisations multiplient les étapes de validation : validation métier, validation data, validation IT, validation conformité, validation comité, et parfois validation du comité du comité. Chaque changement, même mineur, doit passer par un circuit long et formel.
Si cette approche peut rassurer sur le papier, elle crée rapidement une inertie opérationnelle. Les équipes contournent les processus pour aller plus vite, ou renoncent à certaines améliorations parce que le coût administratif devient trop élevé par rapport au bénéfice attendu.
La gouvernance doit proportionner le niveau de validation au niveau de risque. Sinon, elle transforme un projet agile en parcours d’obstacles.
Lorsque la gouvernance ajoute des niveaux hiérarchiques supplémentaires sans clarifier les rôles, la prise de décision devient floue. Qui décide vraiment ? Qui arbitre en cas de désaccord ? À quel moment le sujet peut-il avancer ?
Un excès de couches décisionnelles ralentit les arbitrages et crée une dilution des responsabilités. Plus il y a d’instances, plus le risque est grand que personne ne se sente réellement décisionnaire. Et paradoxalement, plus on cherche à structurer, plus on complexifie.
Une gouvernance efficace cherche au contraire à simplifier : identifier le bon niveau de décision, et éviter que chaque sujet stratégique devienne une affaire interminable.
La gouvernance peut parfois dériver vers une accumulation de documents, de chartes, de matrices et de comptes rendus qui rassurent, mais qui ne sont jamais réellement utilisés. On produit beaucoup, on formalise beaucoup, mais l’impact opérationnel reste limité.
Dans ce cas, la gouvernance devient un exercice administratif plutôt qu’un levier stratégique. Les équipes perçoivent alors le dispositif comme une contrainte éloignée de leurs besoins quotidiens, et la dynamique s’essouffle.
Une gouvernance utile n’est pas celle qui produit le plus de documents, mais celle qui clarifie les décisions et facilite les projets. Le but n’est pas d’ajouter des couches, mais de rendre les règles compréhensibles et applicables. Sinon, on finit par gouverner la gouvernance, ce qui est rarement l’objectif initial.
Dans une entreprise B2B, le marketing, le commerce et la finance utilisent tous l’indicateur “lead qualifié”. Problème : chacun a sa propre définition. Le marketing se base sur un score, le commerce sur un contact validé, la finance exclut certains partenaires. Résultat : trois chiffres différents pour un même KPI en comité de direction. La gouvernance est nécessaire pour trancher et stabiliser une définition commune. Mais si le processus d’arbitrage est trop lourd, les équipes continueront à produire leurs propres versions en parallèle — et le problème restera entier.
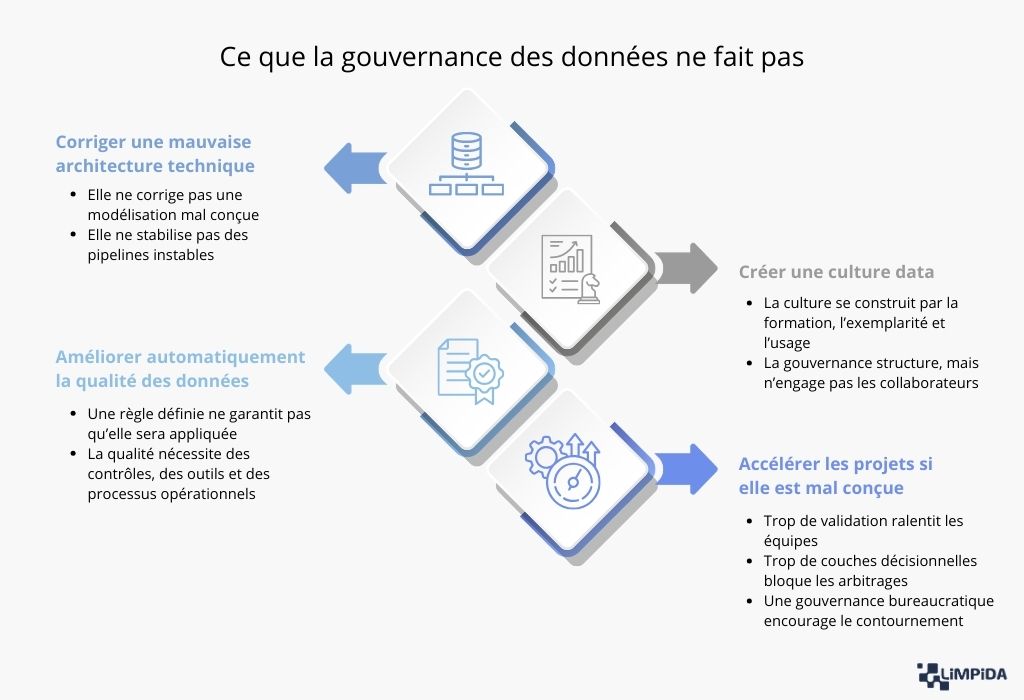
Avant même d’entrer dans les détails, il faut reconnaître une chose : si la gouvernance des données crée autant de débats, c’est parce qu’elle est souvent mal définie, mal positionnée ou mal comprise. Elle se situe à la frontière entre organisation, technique, conformité et performance. Et cette position hybride entretient naturellement les malentendus.
👉À lire aussi : Gouvernance des données : 5 erreurs fréquentes qui limitent votre impact
En pratique, la confusion vient souvent de quatre sources :
Ces confusions ne sont pas anodines : elles influencent directement la manière dont les organisations conçoivent, déploient — et parfois rejettent — la gouvernance des données. Prenons le temps de les clarifier.
La première confusion vient du fait que la gouvernance des données est souvent assimilée au data management dans son ensemble. Or, le data management regroupe toutes les activités opérationnelles liées à la collecte, au stockage, à la transformation, à la documentation ou encore à la sécurisation des données. La gouvernance, elle, ne réalise pas ces activités : elle définit le cadre dans lequel elles doivent être réalisées. Elle organise les responsabilités, pose les règles et structure les décisions.
Dans les faits, cette confusion conduit souvent à des attentes mal calibrées. Lorsqu’un programme de gouvernance est lancé, certains s’attendent à voir apparaître rapidement des améliorations techniques, des pipelines plus robustes ou des modèles mieux structurés. Mais si ces chantiers ne sont pas traités par les équipes d’ingénierie ou de data management, la gouvernance, seule, ne peut pas les produire. Elle peut prioriser, cadrer, arbitrer — mais elle ne développe pas les flux ni les modèles.
C’est un peu comme confondre le plan d’urbanisme avec les travaux eux-mêmes. Le plan est indispensable pour éviter le chaos, mais il ne pose pas les briques. Attendre de la gouvernance qu’elle fasse du data management, c’est lui attribuer un rôle qui n’est pas le sien — et c’est souvent la première source de frustration.
👉À lire aussi : Qu’est-ce que le Master Data Management (MDM) ?
Autre amalgame fréquent : considérer la gouvernance comme un programme de qualité des données. Certes, les deux sujets sont liés. La gouvernance peut définir des seuils d’acceptabilité, désigner des responsables qualité, prioriser des domaines critiques. Mais elle ne nettoie pas les données, ne corrige pas les doublons et n’automatise pas les contrôles.
Dans beaucoup d’organisations, la qualité devient le symptôme visible d’un problème plus large. Les erreurs s’accumulent, les chiffres divergent, les équipes perdent confiance. On lance alors un programme de gouvernance en espérant que la situation s’améliore mécaniquement. Or, sans contrôles techniques, sans outils adaptés et sans processus opérationnels de correction, la qualité ne progressera pas durablement.
La gouvernance peut créer un cadre pour la qualité, mais elle ne la fabrique pas. Confondre les deux revient à croire qu’un règlement intérieur suffit à rendre un bâtiment propre. Il aide à structurer les responsabilités, certes, mais quelqu’un doit toujours passer le balai.
Il est également fréquent d’associer la gouvernance à un outil spécifique : catalogue de données, solution de MDM, plateforme de data quality, workflow de validation. Ces outils peuvent être d’excellents supports, mais ils ne constituent pas la gouvernance en eux-mêmes.
Installer un catalogue ne clarifie pas automatiquement qui valide une définition. Déployer un MDM ne résout pas les divergences métier si personne n’est légitime pour arbitrer. Un outil peut formaliser et diffuser les règles, mais il ne les décide pas. La gouvernance précède l’outil ; elle définit les principes que l’outil doit soutenir.
Lorsque l’on commence par la technologie sans avoir clarifié les responsabilités et les processus, on risque simplement de digitaliser le flou existant. Et un flou bien outillé reste un flou.
Avant de sélectionner un catalogue, un MDM ou une plateforme de data quality, commencez par clarifier les rôles, les responsabilités et les processus d’arbitrage. Sinon, l’outil risque de devenir une vitrine bien remplie mais sans propriétaire, sans validation et sans usage réel. Un bon réflexe consiste à démarrer par un périmètre limité (un domaine de données, quelques KPI stratégiques), à stabiliser les décisions, puis à outiller progressivement. En gouvernance, un outil est un accélérateur — pas un point de départ.
Enfin, la gouvernance est parfois enfermée dans une vision trop technique ou trop réglementaire. Soit elle est pilotée exclusivement par l’IT, et perçue comme un sujet d’architecture ou de sécurité. Soit elle est portée principalement par la conformité, et assimilée à une contrainte juridique.
Dans les deux cas, les métiers peuvent se sentir peu concernés. La gouvernance devient alors un projet “de support”, éloigné des enjeux business. Or, la donnée est d’abord un actif stratégique. Si les métiers ne sont pas impliqués dans les décisions de définition, de priorité et d’usage, la gouvernance perd une grande partie de sa raison d’être.
La gouvernance des données ne peut ni être uniquement technique, ni uniquement réglementaire. Elle doit être transverse. Sinon, elle devient soit un chantier IT de plus, soit un dispositif de conformité supplémentaire — et dans les deux cas, elle risque de manquer sa cible.
La gouvernance des données n’est ni un projet accessoire, ni un simple dispositif administratif. Elle constitue un cadre structurant qui permet à une organisation de rendre la donnée réellement pilotable : avec des responsabilités explicites, des définitions stabilisées, des règles assumées et des usages sécurisés. Elle apporte de la clarté là où, sans cadre, les décisions se prennent souvent de manière implicite, au fil des urgences et des arbitrages informels.
Pour autant, elle ne doit pas être idéalisée. La gouvernance ne corrige pas une architecture mal conçue, ne stabilise pas un pipeline défaillant et n’améliore pas automatiquement la qualité des données. Elle ne crée pas non plus, à elle seule, une culture data forte. En revanche, elle rend ces transformations possibles, cohérentes et durables. Elle ne produit pas la valeur directement, mais elle évite que la valeur produite soit fragile, incohérente ou dépendante de quelques individus.
Dès lors, avant de lancer (ou de renforcer) une démarche de gouvernance, il est utile de se poser quelques questions simples. Non pas pour complexifier la réflexion, mais pour s’assurer que l’on construit un cadre pertinent, proportionné et réellement utile.
👉À lire aussi : Gouvernance des données : ce qu'il faut piloter (et ce qu'il ne sert à rien de mesurer)
Ces questions ne visent pas à rendre la gouvernance plus lourde. Elles permettent au contraire de revenir à l’essentiel : mettre en place un cadre proportionné, orienté vers la clarté et la cohérence.
Concrètement, une gouvernance bien positionnée permet plusieurs avancées majeures. Elle ne résout pas tout, mais elle crée les conditions nécessaires pour que la donnée devienne un actif réellement maîtrisé.
À l’inverse, certaines attentes doivent être écartées. La gouvernance n’est pas une solution universelle. Elle joue un rôle précis, et c’est justement parce qu’elle reste à sa place qu’elle est efficace.
| Domaine | Ce que la gouvernance permet | Ce qu’elle ne remplace pas |
|---|---|---|
| Responsabilités | Clarifier qui décide et qui arbitre | Le travail opérationnel des équipes |
| Définitions & KPI | Aligner les règles de calcul et les périmètres | Les choix stratégiques eux-mêmes |
| Risque & conformité | Structurer les règles d’accès et la traçabilité | Les actions juridiques ou techniques concrètes |
| Qualité des données | Prioriser et encadrer les exigences | Les contrôles, nettoyages et outils qualité |
| Architecture & pipelines | Encadrer les standards et les décisions | L’ingénierie et la robustesse technique |
| Culture data | Donner un cadre commun | L’adhésion et la formation des collaborateurs |
En définitive, la gouvernance des données n’est ni une contrainte inutile, ni une solution miracle. C’est un cadre. Et comme tout cadre, il n’a de valeur que s’il est compris, proportionné et aligné avec les enjeux réels de l’organisation. Trop faible, il laisse place au flou. Trop lourd, il bloque l’initiative. Bien calibré, il permet enfin de parler de la donnée non pas comme d’un problème mais comme d’un actif maîtrisé.
La gouvernance des données sert à organiser la manière dont une entreprise décide, arbitre et applique ses règles liées à la donnée. Elle permet de clarifier qui est responsable, qui valide les définitions, et comment les règles évoluent dans le temps. Elle ne réalise pas les activités opérationnelles : elle définit le cadre dans lequel elles doivent être réalisées.
Une gouvernance bien conçue agit sur quatre dimensions complémentaires. Elle ne fait pas le travail à la place des équipes, mais elle évite que les décisions critiques se prennent sans cadre, sans responsable, sans traçabilité et sans alignement. Ces quatre utilités structurent l'organisation autour de la donnée et conditionnent la viabilité des projets data dans le temps.
La gouvernance des données ne corrige pas directement la qualité des données, mais elle peut créer les conditions nécessaires pour l'améliorer durablement. Elle pose les exigences, mais leur application repose sur des mécanismes opérationnels concrets (contrôles automatiques, workflows de correction, outils spécialisés). Croire qu'un programme de gouvernance suffira à "améliorer la qualité" sans action technique, c'est confondre cadre et exécution.
Le data management correspond aux activités opérationnelles : collecter, stocker, transformer, documenter, sécuriser et distribuer les données. La gouvernance des données correspond au cadre de décision : elle définit qui décide des règles, qui arbitre les divergences, et comment les responsabilités sont structurées. Autrement dit : le data management exécute, tandis que la gouvernance organise et pilote.
Non. La gouvernance des données n'est pas un outil. Un catalogue, un glossaire, une solution MDM ou une plateforme de data quality peuvent soutenir une démarche de gouvernance, mais ils ne créent pas la gouvernance à eux seuls. Sans responsabilités claires et processus d'arbitrage, un outil ne fait souvent que formaliser le désordre existant. La gouvernance doit donc précéder l'outillage, pas l'inverse.
La gouvernance des données ne sert pas à "réparer" automatiquement une organisation data. Elle ne remplace ni l'ingénierie, ni la modélisation, ni les outils. Elle peut structurer les responsabilités et sécuriser les usages, mais elle ne corrige pas ce qui est techniquement ou culturellement cassé. Confondre cadre et exécution est l'une des plus grandes sources de déception dans les programmes de gouvernance.
La gouvernance des données devient bureaucratique lorsqu'elle est conçue comme un empilement de validations, de comités et de documents, sans lien direct avec les usages et les décisions. Ce n'est pas la gouvernance en soi qui pose problème, mais la manière dont elle est déployée. Une gouvernance efficace cherche au contraire à simplifier la prise de décision, pas à l'alourdir.
La gouvernance des données génère de la confusion parce qu'elle se situe à la frontière entre organisation, technique, conformité et performance. Cette position hybride entretient naturellement les malentendus, et beaucoup d'entreprises lui attribuent des objectifs trop larges. Croire que "lancer une gouvernance" suffira à résoudre des problèmes techniques ou opérationnels conduit inévitablement à la déception.



.jpg)


.jpg)







.jpg)
.jpg)


.jpg)




.jpg)


.jpg)





























.jpg)
.jpg)
.jpg)
.jpg)



%20copie.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)














.jpg)




