IA
Pourquoi copier la gouvernance des données pour l’IA est une erreur ?
.png)
23/1/2026
L’IA s’invite aujourd’hui dans presque toutes les organisations, souvent plus vite que les cadres censés l’encadrer. Face à cette accélération, une question revient systématiquement : comment gouverner ces nouveaux usages sans freiner l’innovation ? La réponse la plus courante consiste à s’appuyer sur l’existant et à appliquer à l’IA les règles de gouvernance des données déjà en place. Le raisonnement paraît logique — l’IA consomme des données, donc gouverner les données devrait suffire. Pourtant, cette approche repose sur une confusion fondamentale. Elle donne une impression de maîtrise, rassurante à court terme, mais laisse de côté des risques et des responsabilités qui ne relèvent plus uniquement de la donnée. C’est là que le problème commence.
La confusion entre gouvernance des données et gouvernance de l’IA ne vient pas d’un manque de maturité ou de compétence. Elle vient d’un enchaînement logique d’idées, cohérent en apparence, mais incomplet. Les organisations cherchent à sécuriser rapidement des projets d’IA qui montent en puissance, et se tournent naturellement vers les cadres qu’elles connaissent déjà.
Cette proximité apparente entre données et IA masque toutefois une différence de nature. Gouverner un actif informationnel et gouverner un système décisionnel ne répondent pas aux mêmes logiques, ni aux mêmes risques. Tant que cette distinction n’est pas posée clairement, les cadres de gouvernance ont tendance à glisser vers des angles morts.
Les projets d’IA se sont progressivement déplacés du périmètre expérimental vers le cœur des activités opérationnelles. Là où l’IA servait auparavant à explorer, tester ou assister ponctuellement, elle intervient désormais dans des processus récurrents, parfois critiques, avec des impacts directs sur les clients, les collaborateurs ou les décisions stratégiques.
Cette accélération s’explique par des facteurs très concrets : industrialisation des plateformes cloud, accessibilité accrue des outils de machine learning et pression concurrentielle forte sur les usages avancés de la donnée. Le résultat est simple : plus de modèles, déployés plus vite, par davantage d’équipes, souvent sans que le cadre de gouvernance ait eu le temps d’évoluer au même rythme.
On parle d’accélération des projets d’IA lorsque des modèles passent rapidement du stade expérimental à des usages opérationnels, avec des cycles de conception, de déploiement et d’itération de plus en plus courts, et des impacts directs sur les processus métiers et les décisions. Cette accélération ne concerne pas seulement la vitesse de développement, mais surtout la rapidité avec laquelle l’IA influence des actions concrètes, parfois sans cadre de gouvernance encore stabilisé.
Face à cette montée en puissance, les organisations s’appuient sur ce qu’elles ont déjà structuré. La gouvernance des données fournit des rôles, des comités, des processus de validation, des règles de qualité et de conformité qui ont fait leurs preuves sur les usages analytiques et réglementaires.
Ce réflexe est rationnel. Il permet d’éviter de repartir de zéro, de rassurer les parties prenantes et de donner rapidement un cadre aux projets d’IA. Mais en transposant tel quel ces mécanismes, on gouverne surtout les données en amont, sans réellement adresser ce que fait le modèle, comment il se comporte une fois en production et quelles décisions il influence réellement.
La tentation est logique parce que l’IA dépend des données pour fonctionner. Sans données de qualité, pas de modèle fiable. Mais réduire la gouvernance de l’IA à une extension de la gouvernance des données revient à confondre la matière première et la machine qui la transforme.
En pratique, cette approche donne une illusion de contrôle. Les données sont tracées, sécurisées, documentées, mais le fonctionnement du modèle, ses évolutions dans le temps et ses effets concrets sur les décisions restent largement hors champ. Autrement dit, tout est bien cadré… sauf ce qui pose réellement problème quand l’IA se trompe, discrimine ou automatise une décision contestable.

La gouvernance des données s’est construite pour répondre à des problématiques très précises, souvent sous l’effet de contraintes réglementaires, de besoins de fiabilisation des reportings et de montée en maturité des usages analytiques. Elle vise avant tout à rendre la donnée exploitable, fiable et maîtrisée dans le temps, quel que soit le métier qui l’utilise.
Ce cadre est robuste et indispensable, mais il a été pensé pour gouverner des actifs informationnels et leurs usages humains. Pour comprendre pourquoi il atteint rapidement ses limites face à l’IA, il est nécessaire de rappeler ce qu’il couvre réellement, et ce qu’il ne cherche pas à couvrir.
La gouvernance des données a pour objectif premier de créer un socle de confiance autour des données de l’organisation. Elle permet de s’assurer que les données utilisées pour piloter l’activité, produire des analyses ou répondre à des obligations réglementaires sont cohérentes, compréhensibles et utilisables dans la durée. Sans ce cadre, les décisions reposent sur des chiffres contestables et les arbitrages deviennent rapidement politiques plutôt que factuels.
Elle vise également à clarifier les responsabilités. Qui est responsable de la donnée, qui peut la modifier, qui peut l’utiliser et dans quel contexte. Cette clarification est essentielle pour éviter les zones grises, notamment lorsque les données circulent entre plusieurs métiers, outils ou entités, ce qui est aujourd’hui la norme dans la majorité des organisations.
La gouvernance des données vise en premier lieu à garantir que les données utilisées par l’organisation sont suffisamment fiables pour soutenir les usages métiers, qu’ils soient analytiques, opérationnels ou décisionnels.
Au final, la gouvernance des données cherche moins la perfection que la fiabilité suffisante pour permettre des décisions éclairées et assumées.
👉 À lire aussi : Quels KPI pour suivre la qualité des données ?
Un autre pilier fondamental de la gouvernance des données concerne la maîtrise des accès, des usages et du respect des obligations légales associées aux données, en particulier lorsqu’elles sont sensibles ou personnelles.
Cette approche transforme la conformité d’une contrainte subie en un cadre maîtrisé, intégré aux pratiques courantes.
La gouvernance des données repose enfin sur un principe clé : rendre les usages de la donnée compréhensibles et attribuables, afin d’éviter les zones grises en cas de problème.
Cette traçabilité et cette clarification des responsabilités constituent le socle d’une gouvernance des données robuste, mais elles montrent aussi rapidement leurs limites dès que l’on sort du périmètre strict de la donnée.
Documenter la chaîne de responsabilité directement là où la donnée est utilisée (catalogue, outil BI, pipeline), et non dans un document de gouvernance à part. La responsabilité doit être visible au moment où la question se pose, pas après recherche. Quand l’information est accessible au même endroit que la donnée, la traçabilité devient un réflexe. Sinon, elle reste une intention.
Pour bien comprendre où la gouvernance des données atteint ses limites, il est utile de regarder non pas ce qu’elle fait mal, mais ce pour quoi elle n’a tout simplement pas été conçue. Elle reste extrêmement efficace dans son périmètre historique, mais ce périmètre s’arrête avant le cœur des problématiques liées à l’IA.
Ce que la gouvernance des données sait faire
Ce qu’elle ne sait pas gouverner
Le décalage apparaît ici clairement : la gouvernance des données contrôle ce qui entre dans le système, mais très peu ce qui en sort. Tant que l’humain reste pleinement décisionnaire, ce compromis tient. Dès que l’IA commence à arbitrer, ce cadre montre rapidement ses limites.
L’IA ne change pas seulement la manière dont les données sont exploitées, elle modifie la place même de la technologie dans les processus métiers. Là où la donnée sert principalement à analyser, comprendre et piloter, l’IA intervient directement dans l’action. Cette différence entraîne des conséquences très concrètes sur les usages, les responsabilités et les risques à gouverner.
Autrement dit, gouverner l’IA comme on gouverne la donnée revient à appliquer un cadre pensé pour l’analyse à des systèmes qui participent désormais aux décisions. Le décalage ne se voit pas toujours au départ, mais il finit toujours par apparaître.
Les usages de la donnée sont en général définis en amont, cadrés, documentés et relativement stables dans le temps. Lorsqu’ils évoluent, ces changements sont visibles, discutés et souvent arbitrés dans des instances identifiées.
Avec l’IA, les usages se construisent souvent après le déploiement. Un modèle est intégré dans un outil, testé sur un cas précis, puis progressivement utilisé ailleurs, par d’autres équipes, pour d’autres décisions. Ce glissement est rarement formalisé, parce qu’il ne pose pas de problème immédiat.
Ce caractère mouvant complique fortement la gouvernance. Le risque ne vient pas d’un usage volontairement détourné, mais d’une accumulation de petits décalages entre l’intention initiale et l’usage réel. Et comme tout fonctionne correctement, personne ne pense à remettre le cadre à jour.
Une donnée reste fondamentalement stable. Elle peut être mise à jour ou corrigée, mais elle ne change pas de comportement sans action explicite. Cette stabilité permet de définir des règles de gouvernance durables et des contrôles relativement simples à maintenir.
Un système d’IA, à l’inverse, est conçu pour évoluer. Il apprend à partir des données, peut être réentraîné, ajusté ou influencé par de nouveaux contextes d’usage. Son comportement peut donc changer sans modification visible du périmètre fonctionnel.
Cette dynamique pose un problème simple : un modèle validé à un instant donné ne le reste pas nécessairement dans la durée. La gouvernance ne peut donc pas se limiter à une validation initiale, aussi rigoureuse soit-elle, sous peine de piloter des systèmes dont le comportement réel échappe progressivement au cadre prévu.
Dans les usages data classiques, la donnée éclaire la décision, mais ne la prend pas. La responsabilité reste clairement humaine, même lorsque les outils sont très automatisés ou sophistiqués.
Avec l’IA, cette frontière devient moins nette. Les décisions peuvent être recommandées, priorisées ou déclenchées automatiquement. L’humain reste présent, mais son rôle peut se réduire à une validation rapide, surtout lorsque le système s’impose comme fiable et efficace.
Cette évolution change profondément la nature des risques. Il ne s’agit plus seulement de savoir si la donnée est correcte, mais de comprendre comment une décision est produite, à quel moment l’humain peut intervenir, et qui assume réellement la responsabilité lorsque le résultat pose question.
Considérer l’IA comme une simple extension des usages analytiques de la donnée. Cette approche conduit à gouverner principalement les données en entrée, sans encadrer suffisamment les usages réels, l’évolution des modèles et les décisions produites. Tant que l’IA reste marginale, cette confusion passe. Lorsqu’elle devient structurante, elle crée des angles morts difficiles à rattraper.
Appliquer à l’IA une gouvernance pensée pour la donnée donne rapidement un sentiment de sécurité. Les données sont contrôlées, documentées, conformes. Pourtant, cette approche laisse de côté une série de risques spécifiques, qui n’apparaissent pas dans les cadres traditionnels de gouvernance des données, simplement parce qu’ils n’existaient pas sous cette forme auparavant.
Le danger n’est donc pas une mauvaise gouvernance, mais une gouvernance incomplète. Elle traite correctement les problèmes connus, tout en ignorant des risques nouveaux, souvent plus difficiles à détecter et à expliquer.
La gouvernance des données s’intéresse principalement à ce qui entre dans les systèmes : qualité, conformité, sécurité, traçabilité. L’IA, elle, crée des risques liés à ce que le système produit, à la manière dont il influence les décisions et à la façon dont il est réellement utilisé dans le temps.
Ces risques ne sont ni théoriques ni marginaux. Ils apparaissent dès que l’IA est intégrée dans des processus métiers concrets, en particulier lorsqu’elle automatise ou oriente des décisions ayant un impact sur des personnes, des clients ou des opérations.
La gouvernance des données permet de vérifier que les données sont complètes, conformes et, dans une certaine mesure, représentatives. Cela donne l’impression que les risques de biais sont maîtrisés dès lors que les jeux de données respectent les règles établies.
Avec l’IA, cette assurance est trompeuse. Les biais ne se logent pas uniquement dans les données prises isolément, mais dans la manière dont le modèle les combine, les hiérarchise et les transforme en décisions.
| Ce que couvre la gouvernance des données | Ce que le risque IA introduit |
|---|---|
| Vérification de la qualité et de la représentativité des données | Amplification ou création de biais lors de l’entraînement des modèles |
| Conformité des données sources | Discrimination indirecte dans les décisions produites |
| Contrôle des données sensibles | Corrélations non explicites menant à des effets discriminants |
Un modèle peut donc être entraîné sur des données parfaitement conformes et produire malgré tout des décisions biaisées. Copier la gouvernance des données revient ici à vérifier soigneusement les fondations, pour découvrir un peu tard que l’étage n’est pas tout à fait droit.
La gouvernance des données repose sur des principes de traçabilité et de transparence. En théorie, il est possible de comprendre d’où vient une donnée, comment elle a été transformée et pourquoi un résultat a été produit.
L’IA introduit une rupture nette sur ce point. Certains modèles produisent des résultats efficaces, mais difficiles à expliquer de manière claire et intelligible, y compris pour leurs concepteurs.
| Ce que couvre la gouvernance des données | Ce que le risque IA introduit |
|---|---|
| Traçabilité des sources et des transformations | Difficulté à expliquer pourquoi une décision est prise |
| Documentation des jeux de données | Modèles au raisonnement opaque |
| Capacité à auditer les flux de données | Incapacité à justifier une décision en cas de contestation |
Dans ce contexte, gouverner la donnée ne suffit pas à gouverner la décision. Et expliquer qu’un modèle est « globalement performant » aide rarement lorsqu’il faut justifier une décision précise, prise à un instant donné, pour une personne bien réelle.
La gouvernance des données encadre les usages déclarés : finalités, périmètre, conditions d’utilisation. Ce cadre fonctionne tant que les usages restent stables et explicitement définis.
Avec l’IA, les usages évoluent souvent de manière progressive et informelle. Un modèle peut être réutilisé, étendu ou détourné sans modification technique majeure, simplement parce qu’il fonctionne bien et qu’il est déjà intégré aux outils existants.
| Ce que couvre la gouvernance des données | Ce que le risque IA introduit |
|---|---|
| Encadrement des usages déclarés | Utilisations étendues sans validation |
| Respect des finalités initiales | Glissement progressif des usages réels |
| Contrôle des accès aux données | Dépendance excessive aux recommandations de l’IA |
Le risque n’est pas une mauvaise intention, mais une banalisation progressive de l’IA dans des contextes pour lesquels elle n’a jamais été évaluée. Et lorsqu’un outil devient indispensable, on se pose rarement la question de savoir s’il aurait dû l’être.
Une banque déploie un modèle d’IA pour recommander l’acceptation ou le refus de dossiers de crédit, avec une validation humaine obligatoire. Dans les faits, les conseillers suivent systématiquement la recommandation, car le modèle est perçu comme plus fiable et plus rapide. Progressivement, la validation humaine devient automatique. Les refus sont appliqués sans analyse complémentaire, alors que ce n’était pas l’intention initiale. Du point de vue de la gouvernance des données, tout est conforme. Du point de vue de l’usage, la décision est devenue quasi automatisée.
Dans un cadre de gouvernance des données classique, les responsabilités sont relativement bien identifiées. Un jeu de données à un propriétaire, un steward, des règles de qualité et des usages définis. En cas de problème, le chemin de la responsabilité est rarement élégant, mais il existe. Quelqu’un finit toujours par être identifié, même si ce n’est pas toujours la personne la plus ravie de l’être.
Avec l’IA, cette clarté s’estompe rapidement. Le résultat produit par un modèle est le fruit d’une chaîne complexe impliquant données, algorithmes, paramètres, choix techniques et décisions d’intégration métier. Lorsqu’une décision pose problème, la question de la responsabilité devient moins évidente. Est-ce la donnée d’entraînement, le modèle, l’équipe data, le métier qui l’utilise, ou l’organisation qui a décidé d’automatiser ? Copier la gouvernance des données dans ce contexte revient à chercher un responsable dans un système qui n’a pas été conçu pour en désigner un clairement.
Cette dilution des responsabilités est d’autant plus problématique que les décisions issues de l’IA peuvent avoir des impacts concrets et parfois sensibles. Plus un système est perçu comme objectif, performant ou « scientifique », plus il est difficile de le contester, et plus la responsabilité humaine tend à s’effacer. Le risque n’est pas que personne ne décide, mais que tout le monde décide un peu, ce qui revient souvent au même lorsqu’un problème survient.
La gouvernance des données s’est construite autour d’objets dont le comportement est relativement stable dans le temps. Une fois collectée, transformée et contrôlée, la donnée ne prend pas d’initiative. Elle reste ce qu’elle est, jusqu’à ce qu’un humain décide de la corriger ou de la remplacer. Cette stabilité permet d’installer des règles durables, des rôles clairs et des contrôles positionnés à des moments précis du cycle.
C’est précisément sur cette base que la gouvernance des données fonctionne bien. Elle repose sur un enchaînement logique d’étapes maîtrisées, avec l’idée implicite qu’une validation réalisée à un instant donné reste valable dans le temps. Tant que la donnée est utilisée comme un support d’analyse ou de pilotage, ce cadre tient sans difficulté particulière.
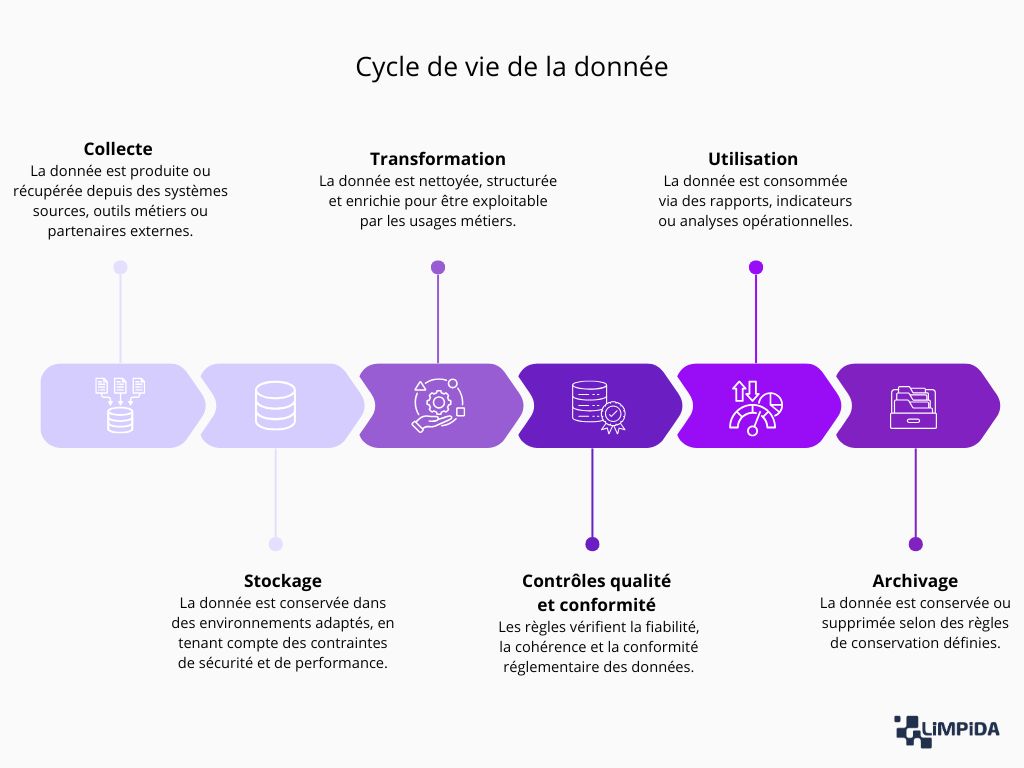
👉 À lire aussi : Le cycle de vie de la donnée : maîtriser les 5 étapes
Un modèle d’IA ne s’inscrit pas dans cette logique. Il évolue en permanence, au fil de son utilisation, de ses ajustements et de son exposition à de nouveaux contextes. Un modèle validé hier peut produire des résultats différents demain, sans qu’aucune règle de qualité des données n’ait été enfreinte. Le système respecte formellement le cadre existant, tout en s’en éloignant progressivement dans les faits.
C’est là que copier la gouvernance des données devient problématique. Les points de contrôle sont positionnés trop tôt ou au mauvais endroit, les responsabilités sont définies pour des objets stables, et la surveillance s’arrête là où elle devrait commencer. La gouvernance n’est pas absente, elle est simplement décalée. Et dans le cas de l’IA, ce décalage suffit à créer des zones de non-couverture durables.

Une fois admis que la gouvernance des données ne suffit pas, la question n’est plus de savoir s’il faut une gouvernance de l’IA, mais ce qu’elle doit réellement couvrir. Gouverner l’IA ne consiste pas à empiler des règles, mais à encadrer des objets et des usages qui n’existaient pas dans les cadres traditionnels.
La gouvernance de l’IA s’attaque donc à des enjeux différents : le comportement des modèles, leur évolution dans le temps, leur influence sur les décisions et la capacité de l’organisation à en répondre. Autrement dit, elle se situe là où la gouvernance des données s’arrête naturellement.
Dans beaucoup d’organisations, le modèle reste traité comme un artefact technique. Une fois entraîné et mis en production, il disparaît derrière les outils métiers, comme si sa gouvernance s’arrêtait au moment du déploiement. La gouvernance des données, elle, considère souvent que son rôle est terminé dès lors que les données d’entrée sont conformes.
Or, dans un système d’IA, le modèle est précisément l’élément qui transforme la donnée en décision. C’est lui qui arbitre, pondère, hiérarchise et parfois simplifie une réalité complexe. Ne pas gouverner le modèle revient à accepter que cette transformation se fasse sans cadre explicite, tant que les résultats paraissent satisfaisants.
Gouverner les modèles implique donc de les considérer comme des objets vivants, avec un cycle de vie propre, des critères de performance multiples et des dérives possibles. Cela suppose de définir quand un modèle est acceptable, quand il doit être revu, ajusté ou retiré, et surtout qui est responsable de ces décisions. Tant que ces questions restent implicites, la gouvernance de l’IA repose davantage sur la confiance que sur un cadre réel.
L’un des enjeux les plus sensibles de la gouvernance de l’IA concerne les usages réels du système. Pas ceux décrits dans les documents de cadrage, mais ceux qui s’installent progressivement dans les pratiques quotidiennes. L’IA influence rarement les décisions de manière brutale. Elle le fait par accumulation, jusqu’à devenir une évidence opérationnelle.
Encadrer l’IA, ce n’est donc pas seulement définir ce que le modèle est censé faire, mais ce qu’il est autorisé à faire. Cela inclut le niveau d’automatisation acceptable, les décisions qui doivent impérativement rester humaines, et les situations dans lesquelles l’IA ne doit servir que de support. Sans ce cadre, la frontière entre assistance et automatisation devient floue, souvent sans que personne ne l’ait vraiment décidée.
Ce point est d’autant plus critique que plus un système fonctionne bien, moins il est remis en question. La gouvernance de l’IA doit donc anticiper ce succès. Elle ne sert pas à corriger les erreurs visibles, mais à encadrer des usages qui, précisément parce qu’ils sont efficaces, finissent par s’imposer sans débat.
La performance d’un modèle ne suffit pas à créer de la confiance durable. Pour être acceptée dans le temps, l’IA doit être compréhensible, explicable et contestable, au moins dans ses grandes lignes. La gouvernance de l’IA joue ici un rôle central, bien au-delà des considérations techniques.
Assurer la transparence ne signifie pas rendre chaque algorithme parfaitement lisible, mais être capable d’expliquer les principes de décision, les limites du système et les situations dans lesquelles ses résultats doivent être interprétés avec prudence. Cette capacité devient essentielle dès qu’une décision est contestée, qu’un client s’interroge ou qu’un régulateur demande des comptes.
La confiance ne se décrète pas, elle se construit. Et paradoxalement, elle repose souvent moins sur la sophistication du modèle que sur la capacité de l’organisation à assumer ses choix. Une gouvernance de l’IA efficace ne promet pas une IA infaillible, mais une IA dont les décisions peuvent être expliquées, discutées et, si nécessaire, remises en cause sans mettre toute l’organisation en difficulté.
À ce stade, le débat n’oppose plus gouvernance des données et gouvernance de l’IA. La question est désormais de comprendre comment ces deux cadres peuvent coexister sans se neutraliser. L’un ne remplace pas l’autre, mais aucun ne suffit à lui seul. C’est précisément dans cette zone d’intersection que les organisations rencontrent le plus de difficultés.
Pour avancer, il faut donc distinguer ce qui peut raisonnablement être partagé, ce qui doit être repensé, et pourquoi cette séparation est une condition de réussite plutôt qu’une complexité supplémentaire.
La gouvernance des données constitue un socle indispensable pour les projets d’IA. Elle permet de sécuriser la matière première sur laquelle reposent les modèles et de garantir un minimum de fiabilité et de conformité dès les premières étapes. À ce titre, plusieurs éléments existants conservent toute leur pertinence dans un contexte d’IA.
Ces éléments permettent de sécuriser ce qui alimente les modèles. Ils évitent de construire des systèmes d’IA sur des données instables ou non conformes. En revanche, ils ne disent rien sur la manière dont les modèles exploitent ces données, ni sur les décisions qui en résultent. La mutualisation trouve donc naturellement ses limites à l’entrée du système.
Dès lors que l’on s’intéresse au fonctionnement du modèle lui-même, la gouvernance des données ne suffit plus. Le modèle n’est pas un simple prolongement de la donnée : il transforme, arbitre et influence des décisions, parfois de manière automatique. Ces dimensions introduisent des enjeux qui nécessitent un cadre dédié.
Ces sujets ne relèvent pas de la qualité des données, mais du comportement du système et de ses effets concrets. Les traiter dans un cadre de gouvernance des données conduit soit à les diluer, soit à les ignorer. Une gouvernance de l’IA doit donc les prendre en charge explicitement, avec des règles, des responsabilités et des mécanismes de suivi adaptés.
👉 À lire aussi : L’IA générative et ses impacts sur la gouvernance des données
La coexistence de deux cadres de gouvernance n’est pas une complexité inutile, mais une réponse pragmatique à des objets fondamentalement différents. Données et modèles ne remplissent pas le même rôle et n’évoluent pas selon les mêmes dynamiques. Chercher à les gouverner de manière identique revient à appliquer un cadre unique à des réalités hétérogènes.
Dans une approche claire et opérationnelle :
L’articulation entre les deux permet de couvrir l’ensemble de la chaîne, depuis les données jusqu’aux décisions, sans faire peser l’ensemble des responsabilités sur un seul cadre. Sans cette distinction, la gouvernance devient soit trop générique pour être efficace, soit trop contraignante pour accompagner les usages réels.
C’est précisément cette séparation, assumée mais coordonnée, qui permet de construire une gouvernance de l’IA lisible, applicable et capable d’évoluer avec les usages, plutôt qu’un dispositif rassurant sur le papier mais fragile dans la pratique.
Identifier, pour chaque projet d’IA, un point de décision explicite : s’agit-il d’un sujet lié aux données (qualité, accès, conformité) ou au comportement du modèle (usage, décision, évolution) ? Cette clarification simple évite que des enjeux liés à l’IA soient traités par défaut comme des problèmes de données.
Poser une gouvernance de l’IA ne consiste pas à produire un cadre exhaustif dès le départ. Il s’agit plutôt d’installer des réflexes structurants, capables d’évoluer avec les usages. Une gouvernance trop ambitieuse dès le départ devient vite théorique. À l’inverse, une gouvernance absente laisse les décisions se prendre ailleurs, souvent sans que personne ne s’en rende compte.
Les premières briques doivent donc être simples, ciblées et directement reliées aux usages réels de l’IA dans l’organisation.
Tous les cas d’usage d’IA ne présentent pas le même niveau de risque, et vouloir les gouverner de manière uniforme est contre-productif. Un modèle utilisé pour optimiser un planning interne ne pose pas les mêmes enjeux qu’un système influençant des décisions de recrutement, de tarification ou d’octroi de droits. La première étape consiste donc à accepter cette hétérogénéité.
Identifier les cas d’usage à risque permet de concentrer l’effort de gouvernance là où il est réellement nécessaire. Cela implique de regarder non seulement la complexité technique du modèle, mais surtout son impact potentiel : qui est concerné par la décision, quelles conséquences en cas d’erreur, quel niveau d’automatisation est en jeu. Une gouvernance efficace commence rarement par les modèles les plus sophistiqués, mais par ceux dont les effets sont les plus sensibles.
Une fois les cas d’usage identifiés, la gouvernance de l’IA doit s’intéresser directement aux modèles. Pas aux données uniquement, mais aux règles qui encadrent leur conception, leur utilisation et leur évolution. Sans cela, le modèle reste un objet technique performant, mais sans cadre décisionnel explicite.
Définir des règles propres aux modèles permet de clarifier ce qui est attendu et ce qui ne l’est pas. Cela concerne par exemple les critères d’acceptabilité, les conditions de mise à jour, les seuils de performance minimum ou les situations nécessitant une revue humaine. L’objectif n’est pas de figer les modèles, mais d’éviter qu’ils évoluent sans cadre, portés uniquement par leur efficacité apparente.
La gouvernance de l’IA ne peut pas reposer uniquement sur les équipes techniques. Dès qu’un modèle influence des décisions métiers, les responsabilités deviennent nécessairement partagées. Pourtant, beaucoup d’organisations continuent à traiter l’IA comme un sujet technique, en espérant régler les questions de gouvernance plus tard.
Impliquer les bons rôles dès le départ permet d’éviter cette dérive. Les métiers, les équipes data, le juridique, la conformité ou encore la sécurité doivent être associés non pas pour ralentir les projets, mais pour clarifier les attentes et les responsabilités. Une gouvernance de l’IA efficace n’est pas celle qui empêche d’avancer, mais celle qui évite de découvrir trop tard que personne ne savait vraiment qui devait décider.
Parce que la gouvernance des données et la gouvernance de l'IA répondent à des logiques différentes. Gouverner un actif informationnel et gouverner un système décisionnel ne traitent pas les mêmes risques. Transposer tel quel un cadre data sur l'IA donne une impression de maîtrise rassurante à court terme, mais laisse de côté tout ce qui pose réellement problème quand l'IA se trompe, discrimine ou automatise une décision contestable.
La gouvernance des données encadre la qualité, la sécurité, la conformité et la traçabilité des données utilisées par l'organisation. La gouvernance de l'IA, elle, s'intéresse au comportement des modèles, à leur évolution dans le temps et aux décisions qu'ils produisent ou influencent. Gouverner l'IA ne revient donc pas à gouverner uniquement la donnée, mais à encadrer un système décisionnel.
Parce qu'elle a été conçue pour des usages analytiques pilotés par des humains, et non pour des systèmes qui automatisent ou orientent directement des décisions. Elle contrôle ce qui entre dans le système (les données), mais très peu ce qui en sort (les décisions, recommandations ou actions déclenchées par l'IA).
Cette approche laisse de côté des risques spécifiques comme les biais algorithmiques, le manque d'explicabilité des décisions, les dérives d'usage après mise en production ou encore la dilution des responsabilités. Les données peuvent être parfaitement conformes tout en produisant, via l'IA, des décisions contestables ou discriminantes. Le danger n'est pas une mauvaise gouvernance, mais une gouvernance incomplète.
Contrairement à la donnée, qui éclaire la décision, l'IA participe directement à l'action. Elle peut recommander, prioriser ou automatiser des choix opérationnels. Cette évolution rend la frontière entre aide à la décision et décision automatisée plus floue, ce qui complexifie fortement les questions de responsabilité et de gouvernance.
Parce que les organisations ont le sentiment de maîtriser leurs projets d'IA dès lors que les données sont de qualité, documentées et conformes. En réalité, le comportement du modèle, ses évolutions et ses impacts concrets échappent souvent à ce cadre, créant des angles morts difficiles à détecter.
La gouvernance des données s'est construite autour d'objets stables : une donnée collectée, transformée et contrôlée ne change pas de comportement sans action explicite. Un modèle d'IA, à l'inverse, est conçu pour évoluer en permanence. Cette différence de cycle de vie a des conséquences directes sur la position et la fréquence des points de contrôle.
Non. Les deux sont complémentaires. La gouvernance des données constitue un socle indispensable pour sécuriser les données d'entrée, tandis que la gouvernance de l'IA doit encadrer spécifiquement les modèles, leurs usages et les décisions produites. L'erreur consiste à vouloir tout faire porter à un seul cadre.
La gouvernance des données constitue un socle indispensable pour les projets d'IA : elle sécurise la matière première sur laquelle reposent les modèles. Plusieurs éléments existants conservent leur pertinence dans un contexte d'IA et peuvent être mutualisés sans repartir de zéro. La mutualisation trouve toutefois ses limites à l'entrée du système : ce qui touche au comportement du modèle nécessite un cadre dédié.
Il est recommandé de commencer par identifier les cas d'usage d'IA à risque, définir des règles propres aux modèles et impliquer dès le départ les rôles métiers, data, juridiques et conformité. Une gouvernance de l'IA efficace ne cherche pas à tout encadrer immédiatement, mais à installer des garde-fous là où les impacts sont les plus sensibles, avec des réflexes structurants capables d'évoluer avec les usages.

.jpg)












.jpg)



.jpg)


.jpg)







.jpg)
.jpg)


.jpg)




.jpg)


.jpg)





























.jpg)
.jpg)
.jpg)
.jpg)



%20copie.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)



